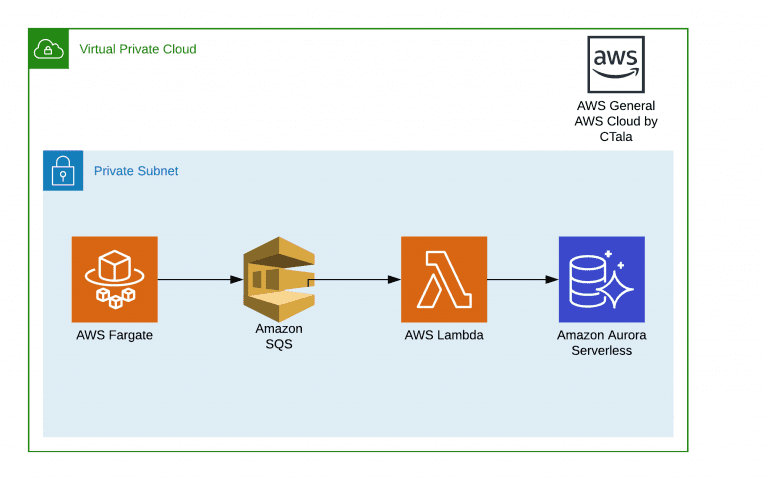
Hace ya casi un año que Amazon publicó que estaban desarrollando el soporte de Amazon SQS como «Event Source» para una función Lambda, y desde que la solución estuvo disponible buscaba una escusa para poder encontrar un mini proyecto para probarla.
Para el desarrollo interno de la empresa tengo un «Bot» que obtiene de manera diaria un CSV con alrededor de 1.000.000 de filas. Para todos los que estamos acostumbrados a trabajar con archivos grandes, 1M de datos no suena tan complejo, por lo que a pesar de tener mejores opciones decidí que era el momento de hacer una prueba de fuego parseando este archivo y enviando el resultado directamente a la cola fila por fila para luego ser procesado a través de una función lambda.
Este post es para comentar sobre la estructura final del proyecto, y como se fue modificando para poder funcionar de manera correcta.